Full Cycle Developers at Netflix — Operate What You Build
The year was 2012 and operating a critical service at Netflix was laborious. Deployments felt like walking through wet sand. Canarying was devolving into verifying endurance (“nothing broke after one week of canarying, let’s push it”) rather than correct functionality. Researching issues felt like bouncing a rubber ball between teams, hard to catch the root cause and harder yet to stop from bouncing between one another. All of these were signs that changes were needed.
Fast forward to 2018. Netflix has grown to 125M global members enjoying 140M+ hours of viewing per day. We’ve invested significantly in improving the development and operations story for our engineering teams. Along the way we’ve experimented with many approaches to building and operating our services. We’d like to share one approach, including its pros and cons, that is relatively common within Netflix. We hope that sharing our experiences inspires others to debate the alternatives and learn from our journey.
One Team’s Journey
Edge Engineering is responsible for the first layer of AWS services that must be up for Netflix streaming to work. In the past, Edge Engineering had ops-focused teams and SRE specialists who owned the deploy+operate+support parts of the software life cycle. Releasing a new feature meant devs coordinating with the ops team on things like metrics, alerts, and capacity considerations, and then handing off code for the ops team to deploy and operate. To be effective at running the code and supporting partners, the ops teams needed ongoing training on new features and bug fixes. The primary upside of having a separate ops team was less developer interrupts when things were going well.
When things didn’t go well, the costs added up. Communication and knowledge transfers between devs and ops/SREs were lossy, requiring additional round trips to debug problems or answer partner questions. Deployment problems had a higher time-to-detect and time-to-resolve due to the ops teams having less direct knowledge of the changes being deployed. The gap between code complete and deployed was much longer than today, with releases happening on the order of weeks rather than days. Feedback went from ops, who directly experienced pains such as lack of alerting/monitoring or performance issues and increased latencies, to devs, who were hearing about those problems second-hand.
To improve on this, Edge Engineering experimented with a hybrid model where devs could push code themselves when needed, and also were responsible for off-hours production issues and support requests. This improved the feedback and learning cycles for developers. But, having only partial responsibility left gaps. For example, even though devs could do their own deployments and debug pipeline breakages, they would often defer to the ops release specialist. For the ops-focused people, they were motivated to do the day to day work but found it hard to prioritize automation so that others didn’t need to rely on them.
In search of a better way, we took a step back and decided to start from first principles. What were we trying to accomplish and why weren’t we being successful?
The Software Life Cycle
The purpose of the software life cycle is to optimize “time to value”; to effectively convert ideas into working products and services for customers. Developing and running a software service involves a full set of responsibilities:

We had been segmenting these responsibilities. At an extreme, this means each functional area is owned by a different person/role:

These specialized roles create efficiencies within each segment while potentially creating inefficiencies across the entire life cycle. Specialists develop expertise in a focused area and optimize what’s needed for that area. They get more effective at solving their piece of the puzzle. But software requires the entire life cycle to deliver value to customers. Having teams of specialists who each own a slice of the life cycle can create silos that slow down end-to-end progress. Grouping differing specialists together into one team can reduce silos, but having different people do each role adds communication overhead, introduces bottlenecks, and inhibits the effectiveness of feedback loops.
Operating What You Build
To rethink our approach, we drew inspiration from the principles of the devops movement. We could optimize for learning and feedback by breaking down silos and encouraging shared ownership of the full software life cycle:

“Operate what you build” puts the devops principles in action by having the team that develops a system also be responsible for operating and supporting that system. Distributing this responsibility to each development team, rather than externalizing it, creates direct feedback loops and aligns incentives. Teams that feel operational pain are empowered to remediate the pain by changing their system design or code; they are responsible and accountable for both functions. Each development team owns deployment issues, performance bugs, capacity planning, alerting gaps, partner support, and so on.
Scaling Through Developer Tools
Ownership of the full development life cycle adds significantly to what software developers are expected to do. Tooling that simplifies and automates common development needs helps to balance this out. For example, if software developers are expected to manage rollbacks of their services, rich tooling is needed that can both detect and alert them of the problems as well as to aid in the rollback.
Netflix created centralized teams (e.g., Cloud Platform, Performance & Reliability Engineering, Engineering Tools) with the mission of developing common tooling and infrastructure to solve problems that every development team has. Those centralized teams act as force multipliers by turning their specialized knowledge into reusable building blocks. For example:

Empowered with these tools in hand, development teams can focus on solving problems within their specific product domain. As additional tooling needs arise, centralized teams assess whether the needs are common across multiple dev teams. When they are, collaborations ensue. Sometimes these local needs are too specific to warrant centralized investment. In that case the development team decides if their need is important enough for them to solve on their own.
Balancing local versus central investment in similar problems is one of the toughest aspects of our approach. In our experience the benefits of finding novel solutions to developer needs are worth the risk of multiple groups creating parallel solutions that will need to converge down the road. Communication and alignment are the keys to success. By starting well-aligned on the needs and how common they are likely to be, we can better match the investment to the benefits to dev teams across Netflix.
Full Cycle Developers
By combining all of these ideas together, we arrived at a model where a development team, equipped with amazing developer productivity tools, is responsible for the full software life cycle: design, development, test, deploy, operate, and support.
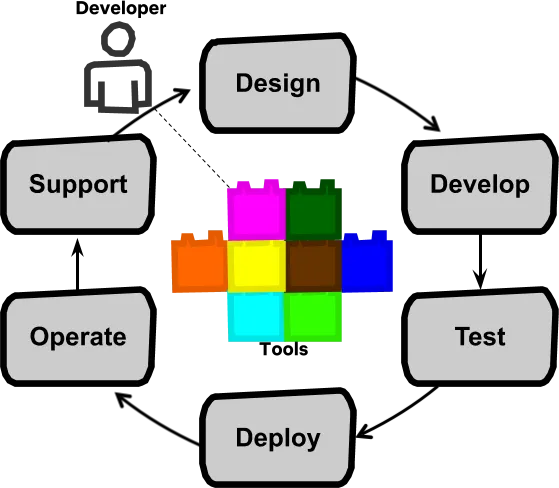
Full cycle developers are expected to be knowledgeable and effective in all areas of the software life cycle. For many new-to-Netflix developers, this means ramping up on areas they haven’t focused on before. We run dev bootcamps and other forms of ongoing training to impart this knowledge and build up these skills. Knowledge is necessary but not sufficient; easy-to-use tools for deployment pipelines (e.g., Spinnaker) and monitoring (e.g., Atlas) are also needed for effective full cycle ownership.
Full cycle developers apply engineering discipline to all areas of the life cycle. They evaluate problems from a developer perspective and ask questions like “how can I automate what is needed to operate this system?” and “what self-service tool will enable my partners to answer their questions without needing me to be involved?” This helps our teams scale by favoring systems-focused rather than humans-focused thinking and automation over manual approaches.
Moving to a full cycle developer model requires a mindset shift. Some developers view design+development, and sometimes testing, as the primary way that they create value. This leads to the anti-pattern of viewing operations as a distraction, favoring short term fixes to operational and support issues so that they can get back to their “real job”. But the “real job” of full cycle developers is to use their software development expertise to solve problems across the full life cycle. A full cycle developer thinks and acts like an SWE, SDET, and SRE. At times they create software that solves business problems, at other times they write test cases for that, and still other times they automate operational aspects of that system.
For this model to succeed, teams must be committed to the value it brings and be cognizant of the costs. Teams need to be staffed appropriately with enough headroom to manage builds and deployments, handle production issues, and respond to partner support requests. Time needs to be devoted to training. Tools need to be leveraged and invested in. Partnerships need to be fostered with centralized teams to create reusable components and solutions. All areas of the life cycle need to be considered during planning and retrospectives. Investments like automating alert responses and building self-service partner support tools need to be prioritized alongside business projects. With appropriate staffing, prioritization, and partnerships, teams can be successful at operating what they build. Without these, teams risk overload and burnout.
To apply this model outside of Netflix, adaptations are necessary. The common problems across your dev teams are likely similar — from the need for continuous delivery pipelines, monitoring/observability, and so on. But many companies won’t have the staffing to invest in centralized teams like at Netflix, nor will they need the complexity that Netflix’s scale requires. Netflix’s tools are often open source, and it may be compelling to try them as a first pass. However, other open source and SaaS solutions to these problems can meet most companies needs. Start with analysis of the potential value and count the costs, followed by the mindset-shift. Evaluate what you need and be mindful of bringing in the least complexity necessary.
Trade-offs
The tech industry has a wide range of ways to solve development and operations needs (see devops topologies for an extensive list). The full cycle model described here is common at Netflix, but has its downsides. Knowing the trade-offs before choosing a model can increase the chance of success.
With the full cycle model, priority is given to a larger area of ownership and effectiveness in those broader domains through tools. Breadth requires both interest and aptitude in a diverse range of technologies. Some developers prefer focusing on becoming world class experts in a narrow field and our industry needs those types of specialists for some areas. For those experts, the need to be broad, with reasonable depth in each area, may be uncomfortable and sometimes unfulfilling. Some at Netflix prefer to be in an area that needs deep expertise without requiring ongoing breadth and we support them in finding those roles; others enjoy and welcome the broader responsibilities.
In our experience with building and operating cloud-based systems, we’ve seen effectiveness with developers who value the breadth that owning the full cycle requires. But that breadth increases each developer’s cognitive load and means a team will balance more priorities every week than if they just focused on one area. We mitigate this by having an on-call rotation where developers take turns handling the deployment + operations + support responsibilities. When done well, that creates space for the others to do the focused, flow-state type work. When not done well, teams devolve into everyone jumping in on high-interrupt work like production issues, which can lead to burnout.
Tooling and automation help to scale expertise, but no tool will solve every problem in the developer productivity and operations space. Netflix has a “paved road” set of tools and practices that are formally supported by centralized teams. We don’t mandate adoption of those paved roads but encourage adoption by ensuring that development and operations using those technologies is a far better experience than not using them. The downside of our approach is that the ideal of “every team using every feature in every tool for their most important needs” is near impossible to achieve. Realizing the returns on investment for our centralized teams’ solutions requires effort, alignment, and ongoing adaptations.
Conclusion
The path from 2012 to today has been full of experiments, learning, and adaptations. Edge Engineering, whose earlier experiences motivated finding a better model, is actively applying the full cycle developer model today. Deployments are routine and frequent, canaries take hours instead of days, and developers can quickly research issues and make changes rather than bouncing the responsibilities across teams. Other groups are seeing similar benefits. However, we’re cognizant that we got here by applying and learning from alternate approaches. We expect tomorrow’s needs to motivate further evolution.
Interested in seeing this model in action? Want to be a part of exploring how we evolve our approaches for the future? Consider joining us.
By Philip Fisher-Ogden, Greg Burrell, and Dianne Marsh

