Implementing Japanese Subtitles on Netflix
Japanese subtitles were first made available on the Netflix service as a part of the Japanese launch in September 2015. This blog post provides a technical description of the work we did leading up to this launch. We cover topics including our specification for source subtitle files, the transformation model from source subtitle files to those deliverable on the Netflix service, the model for delivery of Japanese subtitles on our service as well as the interaction of our work with the upcoming W3C subtitle standard, Timed Text Markup Language 2 (TTML2).
Towards the end of 2014, we were working on the technical features for the planned September 2015 launch of Netflix in Japan. At the time, we were mindful that other streaming services that were operating in the Japanese market had received criticism for providing a substandard subtitle experience. Armed with this knowledge, and our desire to maintain the high Netflix standard of quality, we made a decision to implement rigorous support for all of the “essential” Japanese subtitle features — those that would be customary in a premium Japanese video service. This was on top of our following existing subtitle requirements:
- Subtitles must be delivered to clients separate from the video (i.e. no burned-in subtitles); and
- All subtitle sources must be delivered to Netflix in text format, in order to be future-proof.
Essential Japanese Subtitle Features
Overview
Through a combination of market research, and advice from Japanese language and media experts, we identified five essential Japanese subtitle features. These features (described below) include rubies, boutens, vertical text, slanted text, and “tate-chu-yoko” (horizontal numbers in vertical text). From our perspective, this prelude was indicative of the complexity of the challenge we had at our hand.
Rubies
Ruby annotations describe the base text that they are associated with. They help explain the meaning of unfamiliar, foreign, or slang words/phrases AND/OR convey pronunciation of kanji characters that are rare and/or unknown. They can help provide cultural context to a translation which allows the viewer to enjoy the content with a deeper understanding. Common practice in subtitling is to display rubies in a font size that is smaller relative to the base text and to place them above the base character for single-line subtitles, and for the first line of two-line subtitles. Rubies are placed below the base character if appearing on the second line of a two-line subtitle. Rubies should never be placed between two lines as it is difficult to discern which base character they should be associated with. Figure 1 shows a ruby example for the dialogue “All he ever amounted to was chitlins.”
The base text translates the word “chitlins”*, while the ruby provides transliteration of the word “chitlins” so that viewers can more closely associate the keyword of the dialogue to the translation. As mentioned above, rubies should never be placed in between two lines. Figure 2 shows the proper placement for rubies with two-line subtitles. In the unlikely event that a subtitle spans 3 lines, it is preferable to have the rubies on top of each line, except for the last line where they should be at the bottom.
Boutens
Boutens are dots placed above or below a word or phrase that act as literal points of emphasis, equivalent to the use of italics in English. Boutens can help express implied meanings which provide a richer and more dynamic translation. Figure 3 shows a bouten example for the dialogue: “I need someone to talk to.”
This subtitle has boutens above the word for “talk”. In the context of this scene, placing emphasis on this word allows the viewer to understand the implication that the speaker needs someone to provide him/her with privileged information.
Vertical Subtitles
Vertical subtitles are generally used to avoid overlap with on-screen text present in the video. This is the Japanese equivalent to putting subtitles at the top of the screen. This is illustrated in Figure 4.
Tate-chu-yoko
In Japanese typography, vertical text often includes short runs of horizontal numbers or Latin text. This is referred to as tate-chu-yoko. Instead of stacking the characters vertically, half-width characters are placed side-by-side to enhance legibility and allow more characters to be placed on a single subtitle line. This is illustrated in the Figure 5, for the dialogue, “It’s as if we are still 23 years old”. In this example, subtitle, the number “23” uses half-width numeric characters, and employ the tate-chu-yoko functionality.
Slanted Text
Slanted text is used in similar fashion as italics/oblique text in other languages — for narration, off-screen dialogue, and forced narratives. One unique feature in Japanese subtitles however is that italics slant is in different directions for horizontal vs. vertical subtitles; furthermore, the angle of the slant is not necessarily constant, but may vary. This is illustrated in Figure 6 and Figure 7.
Sourcing Japanese Subtitles
Subtitle assets in the entertainment industry are primarily present in one of two forms — structured text/binary files or rendered images. Netflix has always required the former for its content ingestion system. There are several reasons for this requirement. First, different clients have different subtitle capabilities, requiring us to be able to produce many variations of client assets from a single source. In addition, text subtitle sources are future-proof. That is, as new device capabilities emerge, we can apply those to our large back-catalog of subtitle assets. As an example, when displaying subtitles on an HDR device playing HDR content, it is useful to specify the luminance gain so that white text is not a max-white specular highlight. With text sources, we can easily go back and reprocess to produce subtitles for a client profile that supports luminanceGain. If we had ingested image sources, on the other hand, it would have been difficult to add this sort of functionality to client assets. Further, image assets are opaque while text assets are a lot more amenable for searchability and natural language processing based analysis purposes.
With text sources as a “must-have” requirement, we reviewed the available options for Japanese, and Videotron Lambda (also called ‘LambdaCap’ format) was chosen as the only workable model for Japanese subtitles. There were several reasons for this decision. From our analysis, we determined that the LambdaCap format:
- is reasonably open, allowing us to develop our own tools and workflows.
- is currently the most common subtitle format that Japanese subtitle tools can support. This was a key driver of our decision because it meant that the established Japanese subtitle industry could produce subtitles for Netflix.
- is the most common archive format for existing Japanese subtitles. Another key driver, because supporting LambdaCap meant that we could ingest existing assets without any transformation requirements.
- supports the essential Japanese features as described above.
- has been widely used in the industry to create image-based subtitle files for burn-in. Thus, it is well-tested.
Although we chose the Videotron Lambda model for the Japanese launch, it did not seem like a great long-term option. It is not a de jure industry standard, and there are some ambiguities in the specification. The LambdaCap format supports the essential Japanese subtitling features very well but lacks in some of the rudimentary features supported in Web Platform standards such as TTML1. Examples of such features include color, font information, and also various layout and composition primitives. In addition, we chose to not use LambdaCap as the delivery model to the playback devices in the Netflix eco-system. Concurrently, the timed text working group (TTWG) was working on the second version of the TTML standard (TTML2). One of the stated objectives of TTML2 was the ability to support global subtitles — Japanese subtitles being a key use case. This became a basis for us to collaborate with TTWG on the TTML2 standardization effort including help complete the specification using our experience as well as the implementations described below. TTML2 became the canonical representation for all source formats in our subtitle processing pipeline.
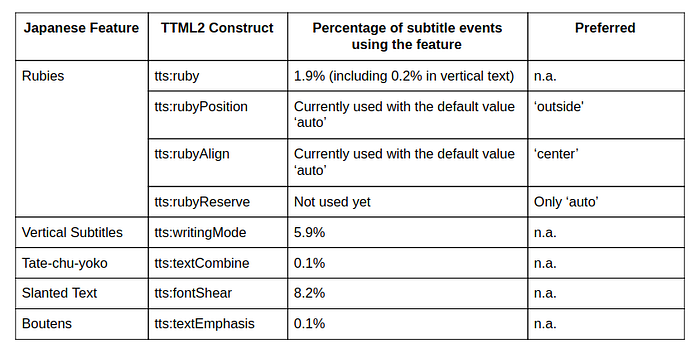
Mapping of Japanese Features to TTML2
Table 1 summarizes the mapping between the essential Japanese subtitling features described above and the constructs offered by TTML2. It also shows the usage statistics for these features across the Netflix Japanese subtitles catalog as well as the preferred mode for their usage in the Netflix eco-system. The other features not yet used or not used significantly are expected to be used more widely in the future†. The following sections provide details on each feature, in particular regarding the supported values.
Rubies
tts:ruby
This styling attribute specifies structural aspects of ruby content including mechanisms that define carriage of ruby base text as well as ruby annotations. The range of values associated with tts:ruby map to corresponding HTML markup elements. As shown in the associated TTML snippet, a ruby “container” markup encompasses both ruby base and annotation text, while ruby “base” and “text” respectively markup base text and annotation text. Figure 8 shows the expected rendering associated with this snippet.
<?xml version="1.0" encoding="utf-8"?>
<tt xmlns="http://www.w3.org/ns/ttml" xmlns:ttm="http://www.w3.org/ns/ttml#metadata" xmlns:ttp="http://www.w3.org/ns/ttml#parameter" xmlns:tts="http://www.w3.org/ns/ttml#styling" ttp:frameRate="30" ttp:frameRateMultiplier="1000 1001" ttp:version="2" tts:extent="1280px 720px" xml:lang="ja">
<head>
<styling>
<initial tts:fontSize="6.0vh" tts:lineHeight="7.5vh" tts:showBackground="whenActive" tts:textOutline="black 0.1em"/>
<style xml:id="s2" tts:textAlign="start"/>
<style xml:id="s3" tts:ruby="container"/>
<style xml:id="s4" tts:ruby="base"/>
<style xml:id="s5" tts:ruby="text" tts:rubyPosition="before"/>
<style xml:id="s7" tts:textAlign="center"/>
<style xml:id="s8" tts:ruby="text" tts:rubyPosition="after"/>
</styling>
<layout>
<region xml:id="横下" tts:displayAlign="after" tts:extent="80vw 30vh" tts:position="center bottom 10vh"/>
</layout>
</head>
<body region="横下" xml:space="preserve">
<div>
<p begin="00:04:30:13" end="00:04:32:18" style="s7"><span style="s2"><span style="s3"><span style="s4">太孫</span><span style="s5">たいそん</span></span>のペクチョンを連れ<br/><span style="s3"><span style="s4">北漢</span><span style="s8">プッカン</span></span>山に登り</span></p>
</div>
</body>
</tt>tts:rubyPosition
This styling attribute specifies positioning of rubies in the block progression dimension relative to the base text. We observed that for the Japanese subtitles use case, tts:rubyPosition=“top” and tts:rubyPosition=“bottom” are less than ideal because they do not provide for unanticipated word wrapping, in which case the second line of text should ideally have rubies below. True to its name, the behavior of tts:rubyPosition=“auto” automatically covers these semantics. This is illustrated in the accompanying TTML snippet. Figure 9 illustrates the expected rendering associated with this snippet. We also note that the behavior of “auto” is currently only specified for exactly two-line events, and will not cover the use case of unanticipated line break on the second line of a two-line event. We believe that that the current behavior described in TTML2 for “outside” is the correct model, and perhaps “auto” could be retired in favor of “outside”.
<?xml version="1.0" encoding="UTF-8"?>
<tt xmlns="http://www.w3.org/ns/ttml" xmlns:tt="http://www.w3.org/ns/ttml" xmlns:ttm="http://www.w3.org/ns/ttml#metadata" xmlns:ttp="http://www.w3.org/ns/ttml#parameter" xmlns:tts="http://www.w3.org/ns/ttml#styling" ttp:tickRate="10000000" ttp:version="2" xml:lang="ja">
<head>
<styling>
<initial tts:backgroundColor="transparent" tts:color="white" tts:fontSize="6.000vh"/>
<style xml:id="style0" tts:textAlign="center"/>
<style xml:id="style1" tts:textAlign="start"/>
<style xml:id="style2" tts:ruby="container" tts:rubyPosition="auto"/>
<style xml:id="style3" tts:ruby="base"/>
<style xml:id="style4" tts:ruby="text"/>
<style xml:id="style5" tts:ruby="text"/>
</styling>
<layout>
<region xml:id="region0" tts:displayAlign="after"/>
</layout>
</head>
<body xml:space="preserve">
<div>
<p xml:id="subtitle1" begin="18637368750t" end="18676157500t" region="region0" style="style0"><span style="style1">テソプ<span style="style2"><span style="style3">の所だ</span><span style="style4">カン食ン</span></span>食おう<br/><span style="style2"><span style="style3">江陵</span><span style="style5">カンヌン</span></span>で刺身でも食おう</span></p>
</div>
</body>
</tt>tts:rubyAlign
This styling attribute specifies the position of ruby text within the inline area that is generated by the ruby container. Given our experience with Japanese subtitles, prefered value of tts:rubyAlign is “center”.
<?xml version="1.0" encoding="utf-8"?>
<tt xmlns="http://www.w3.org/ns/ttml" xmlns:tt="http://www.w3.org/ns/ttml" xmlns:ttm="http://www.w3.org/ns/ttml#metadata" xmlns:ttp="http://www.w3.org/ns/ttml#parameter" xmlns:tts="http://www.w3.org/ns/ttml#styling" ttp:tickRate="10000000" ttp:version="2" xml:lang="ja">
<head>
<styling>
<initial tts:backgroundColor="transparent" tts:color="white" tts:fontSize="6.000vh" tts:lineHeight="7.500vh" tts:opacity="1.000" tts:showBackground="whenActive" tts:writingMode="lrtb" tts:rubyAlign="center"/>
<style xml:id="style0" tts:textAlign="center"/>
<style xml:id="style1" tts:textAlign="start"/>
<style xml:id="style2" tts:ruby="container"/>
<style xml:id="style3" tts:ruby="base"/>
<style xml:id="style4" tts:ruby="text" tts:rubyPosition="auto"/>
</styling>
<layout>
<region xml:id="region0" tts:displayAlign="after" tts:extent="80.000% 30.000%" tts:position="center bottom 10vh" tts:showBackground="whenActive"/>
</layout>
</head>
<body xml:space="preserve">
<div>
<p xml:id="subtitle1" begin="18637368750t" end="18676157500t" region="region0" style="style0"><span style="style1">テソプ<span style="style2"><span style="style3">の所だ</span><span style="style4">カン食ン</span></span>食おう</span></p>
<p xml:id="subtitle2" begin="18676991666t" end="18717031666t" region="region0" style="style0"><span style="style1">テソプ<span style="style2"><span style="style3">の所だ</span><span style="style4">カン食ンカン食ン</span></span>食おう</span></p>
</div>
</body>
</tt>The illustrations below were obtained from the above TTML snippet and they serve to describe the behavior in two cases, when the base text is wider than the ruby text and vice-versa. In both cases, the base text corresponds to ‘の所だ’ (3 Unicode characters) and the ruby alignment value is “center”.
Case 1
In this case (shown in Figure 10), the rendered width of the ruby text is smaller than that of the base text.
Case 2
In this case (shown in Figure 11), the width of the ruby text is greater than the width of the base text. We note that in both the cases, the ruby text is centered with respect to the base text.
tts:rubyReserve
The intent of this feature is to maintain temporal consistency in placement of the base text along the block progression direction as we move from subtitles with only base text to those with base text that is annotated with rubies (and vice versa). We note that this feature can also be used to preserve base text alignment across time when boutens are used.
<?xml version="1.0" encoding="utf-8"?>
<tt xmlns="http://www.w3.org/ns/ttml" xmlns:tt="http://www.w3.org/ns/ttml" xmlns:ttm="http://www.w3.org/ns/ttml#metadata" xmlns:ttp="http://www.w3.org/ns/ttml#parameter" xmlns:tts="http://www.w3.org/ns/ttml#styling" ttp:tickRate="10000000" ttp:version="2" xml:lang="ja">
<head>
<styling>
<initial tts:backgroundColor="transparent" tts:color="white" tts:fontSize="6.000vh" tts:lineHeight="7.500vh" tts:opacity="1.000" tts:showBackground="whenActive" tts:writingMode="lrtb" tts:rubyReserve="auto"/>
<style xml:id="style0" tts:fontShear="16.78842%" tts:textAlign="center"/>
<style xml:id="style1" tts:fontShear="16.78842%" tts:textAlign="start"/>
<style xml:id="style2" tts:fontShear="16.78842%" tts:ruby="container"/>
<style xml:id="style3" tts:fontShear="16.78842%" tts:ruby="base"/>
<style xml:id="style4" tts:fontShear="16.78842%" tts:ruby="text" tts:rubyPosition="auto"/>
</styling>
<layout>
<region xml:id="region0" tts:displayAlign="after" tts:extent="80.000% 30.000%" tts:position="center bottom 10vh" tts:showBackground="whenActive"/>
</layout>
</head>
<body xml:space="preserve">
<div>
<p xml:id="subtitle1" begin="18623187916t" end="18635700416t" region="region0" style="style0"><span style="style1">“行き先は?”</span></p>
<p xml:id="subtitle2" begin="18637368750t" end="18676157500t" region="region0" style="style0"><span style="style1">“テソプの所だ<br/><span style="style2"><span style="style3">江陵</span><span style="style4">カンヌン</span></span>で刺身でも食おう”</span></p>
</div>
</body>
</tt>

The above TTML snippet results in the rendering shown in Figure 12. We note that with tts:rubyReserve enabled, there is no relative movement of subtitles over time.

When tts:rubyReserve is not enabled, the baseline of the base text moves over time resulting in a jarring user experience. This is shown in Figure 13 where there is relative vertical movement between base text from the first subtitle (shown on the left) and the second line of base text from second subtitle (shown on the right).
Vertical Text
Basic vertical text
Netflix relies on the use of tts:writingMode to indicate the vertical writing mode. Below is a sample illustration of vertical text (including specific vertical punctuation and symbols), and a TTML snippet as well as the corresponding rendering (see Figure 14) is provided below.
<?xml version="1.0" encoding="utf-8"?>
<tt xmlns="http://www.w3.org/ns/ttml" xmlns:ttm="http://www.w3.org/ns/ttml#metadata" xmlns:ttp="http://www.w3.org/ns/ttml#parameter" xmlns:tts="http://www.w3.org/ns/ttml#styling" ttp:frameRate="30" ttp:frameRateMultiplier="1000 1001" ttp:version="2" tts:extent="1280px 720px" xml:lang="ja">
<head>
<styling>
<initial tts:fontSize="6.0vh" tts:lineHeight="7.5vh" tts:showBackground="whenActive" tts:textOutline="black 0.1em"/>
<style xml:id="s1" tts:fontShear="16.78842%" tts:textAlign="center"/>
<style xml:id="s2" tts:textAlign="start"/>
<style xml:id="s3" tts:ruby="container"/>
<style xml:id="s4" tts:ruby="base"/>
<style xml:id="s5" tts:ruby="text" tts:rubyPosition="before"/>
<style xml:id="s8" tts:ruby="text" tts:rubyPosition="after"/>
</styling>
<layout>
<region xml:id="縦左" tts:displayAlign="after" tts:extent="30vh 80vh" tts:position="left 10vw center" tts:writingMode="tbrl"/>
</layout>
</head>
<body xml:space="preserve">
<div>
<p begin="00:05:07:23" end="00:05:09:12" region="縦左" style="s1"><span style="s2"><span style="s3"><span style="s4">党項城</span><span style="s5">タンハンじょう</span></span>…現在の<span style="s3"><span style="s4">京畿道</span><span style="s5">キョンギド</span></span>に<br/>位置する城(<span style="s3"><span style="s4">唐</span><span style="s8">タン</span></span>城)</span></p>
</div>
</body>
</tt>Ruby in vertical text
As was shown in the above TTML snippet, the indication of ruby markup in vertical writing mode is no different from that in the horizontal writing mode.
Tate-chu-yoko
tts:textCombine
tts:textCombine is used to realize the “tate-chu-yoko” feature. This is shown in the accompanying TTML snippet. This feature helps increase legibility of subtitles as is shown in the illustration in Figure 15.
<?xml version="1.0" encoding="utf-8"?>
<tt xmlns="http://www.w3.org/ns/ttml" xmlns:ttm="http://www.w3.org/ns/ttml#metadata" xmlns:ttp="http://www.w3.org/ns/ttml#parameter" xmlns:tts="http://www.w3.org/ns/ttml#styling" ttp:frameRate="24" ttp:frameRateMultiplier="1000 1001" ttp:version="2" tts:extent="1280px 720px" xml:lang="ja">
<head>
<styling>
<initial tts:fontSize="6.0vh" tts:lineHeight="7.5vh" tts:showBackground="whenActive" tts:textOutline="black 0.1em"/>
<style xml:id="s1" tts:textCombine="all"/>
<style xml:id="s5" tts:textAlign="center"/>
<style xml:id="s6" tts:textAlign="start"/>
<!-- set up tts:textEmphasis in initial section -->
<style xml:id="s10" tts:textEmphasis="dot after"/>
</styling>
<layout>
<region xml:id="横下" tts:displayAlign="after" tts:extent="80vw 30vh" tts:position="center bottom 10vh"/>
<region xml:id="縦右" tts:extent="30vh 80vh" tts:position="right 10vw center" tts:writingMode="tbrl"/>
</layout>
</head>
<body region="横下" xml:space="preserve">
<div>
<!-- illustration of tts:textCombine in vertical writing mode -->
<p begin="00:00:37:07" end="00:00:40:00" region="縦右">まるで<span style="s1">23</span>歳のままだわ</p>
<!-- illustration of tts:textEmphasis -->
<p begin="00:09:37:14" end="00:09:41:00" style="s5"><span style="s6">もし そうでも<br/><span style="s10">お相手</span>するって</span></p>
</div>
</body>
</tt>Boutens
tts:textEmphasis
This is used for rendering boutens. The TTML snippet in the previous section covers this feature also. The adjacent illustration (Figure 16) shows the corresponding rendering.
Slanted text
tts:fontShear
Japanese typography does not have italics fonts. This behavior is realized by performing geometric transformations on glyphs. The common value of tts:fontShear corresponds to a rotation by nearly 15°. As was noted earlier, the direction of slant varies depending upon the writing mode. This is indicated in the Figure 17 and Figure 18 that are based on the following TTML snippet.
<?xml version="1.0" encoding="utf-8"?>
<tt xmlns="http://www.w3.org/ns/ttml" xmlns:ttm="http://www.w3.org/ns/ttml#metadata" xmlns:ttp="http://www.w3.org/ns/ttml#parameter" xmlns:tts="http://www.w3.org/ns/ttml#styling" ttp:frameRate="30" ttp:frameRateMultiplier="1000 1001" ttp:version="2" tts:extent="1280px 720px" xml:lang="ja">
<head>
<styling>
<initial tts:fontSize="6.0vh" tts:lineHeight="7.5vh" tts:showBackground="whenActive" tts:textOutline="black 0.1em"/>
<style xml:id="s1" tts:fontShear="16.78842%" tts:textAlign="center"/>
<style xml:id="s2" tts:textAlign="start"/>
<style xml:id="s3" tts:ruby="container"/>
<style xml:id="s4" tts:ruby="base"/>
<style xml:id="s5" tts:ruby="text" tts:rubyPosition="before"/>
</styling>
<layout>
<region xml:id="横下" tts:displayAlign="after" tts:extent="80vw 30vh" tts:position="center bottom 10vh"/>
<region xml:id="縦左" tts:displayAlign="after" tts:extent="30vh 80vh" tts:position="left 10vw center" tts:writingMode="tbrl"/>
</layout>
</head>
<body region="横下" xml:space="preserve">
<div>
<p begin="00:01:11:14" end="00:01:15:05" style="s1"><span style="s2">天と地に隔たりのない時</span></p>
<p begin="00:05:04:27" end="00:05:06:28" region="縦左" style="s1"><span style="s2"><span style="s3"><span style="s4">黄草嶺</span><span style="s5">ファンチョリョン</span></span>…現在の<span style="s3"><span style="s4">栄光</span><span style="s5">ヨングァン</span></span>郡に<br/>位置する嶺</span></p>
</div>
</body>
</tt>Subtitle Delivery
Having identified the Japanese feature set and selected a source format, we were able to produce a delivery specification for Japanese subtitle assets. Delivering subtitles to clients was the next problem. Though we were ingesting Japanese subtitles in Videotron Lambda format, for reasons described earlier, we did not feel that LambdaCap format was suitable as a client model. In addition, though we prefer delivering text subtitles to our clients, the large installed base of Netflix Ready Devices could not support the complex Japanese subtitle features. Based on these challenges, we decided to use image subtitles for Japan, and move all of the complexity of rendering Japanese subtitles to our transcoding backend.
This still left us with the challenge of implementing a Japanese subtitle rendering engine to render the image subtitles. For this project, we engaged with Glenn Adams, a Japanese typography expert, and the editor of the W3C TTML specification. The result of our collaboration is the open source software (OSS) Timed Text Toolkit (TTT) project, funded by Netflix, and developed by Skynav. TTT supports all of the essential Japanese subtitle features and in fact, provides a complete set of tools for validation and rendering of TTML2 files. IMSC1 (Internet Media Subtitles and Captions) is a derivative standard from the W3C TTML family, intended for Internet based subtitles and captions delivery applications. When the IMSC1 specification was in development, we were able to use TTT as a full reference implementation, thus helping to drive it to recommendation status. Likewise, TTT provides a full implementation of TTML2, and thus moves us much closer to the completion of that specification.

Using TTT, we implemented a subtitle processing pipeline that converts the source LambdaCap files to a canonical TTML2 representation which was followed by rendering of these subtitles onto images. As shown in Figure 19, the cap2tt module is used to transform a LambdaCap file into a TTML2 document. The TTML2 document is converted into a sequence of images by ttpe. The time sequence of subtitle images is packaged into an archive that also contains timing and positioning information for these images. This archive is delivered to devices in the Netflix eco-system. We also note that these image sets are produced at various target resolutions to cover various screen sizes and device form factors.
Moving Forward
A text-based delivery system is preferable relative to an image-based system in the longer term for various reasons. These include bandwidth efficiency reasons because of the smaller file sizes corresponding to the former case as well as end-user flexibility in terms of choice of font, font size, as well as choice of color. As devices in the Netflix playback eco-system gain more capabilities in terms of their support for Japanese subtitle features, and as the TTML2 standard gathers traction, we intend to migrate to the text-based delivery model. To that end, we are developing a nimble, device-optimized subtitle rendering engine that offers first class support for various TTML2 features.
— by Rohit Puri, Cyril Concolato, David Ronca and Yumi Deeter
(*) Slang word used in “House of Cards”, also known as “Chitterlings”, southern US food usually made from the small intestines of a pig. Such word is unlikely to be known to the audience.
(†) Other TTML2 Japanese features (such as tts:rubyOverhang) not listed in the table are not necessary for the support of Japanese features in the Netflix use-case.

